
“穿黑色夹克、戴棒球帽、背深蓝色双肩包”——仅凭一段目击者模糊的描述,如何在浩如烟海的监控视频中快速锁定目标?绝影V3.0全新推出的文搜图大模型,用“一句话检索”能力彻底变革传统侦查模式,让模糊线索秒变精准坐标!

传统难题:模糊线索如何“大海捞针”?
样本依赖高:传统图像检索需提供清晰目标截图,但紧急案件中往往只有零散文本线索;
筛查效率低下:人工筛查耗时数小时甚至数天,易错过破案黄金时间;
环境容错率低:光线、角度变化导致图像特征失效,检索结果偏差大。
技术揭秘:文搜图大模型的“三大革新”
绝影V3.0搭载文搜图大模型,基于多模态AI技术,实现从“文本”到“视频”的智能跨模态检索:
语义理解更智能
支持自然语言描述(如“白色车、戴口罩等”),自动解析关键特征,实现高精度匹配;
兼容模糊表述,如“浅色外套”、“中等体型”,系统智能泛化检索范围。
跨模态检索更精准
结合视觉特征与语义特征,突破传统以图搜图的局限,即便在目标图像缺失的情况下,仍能实现高效检索。
模糊线索速破案
依托文本描述进行检索,系统自动筛选监控中匹配目标,推送高概率片段,大幅提升侦查响应速度。
实战场景举例
某地盗窃案侦办中,仅凭“货拉拉”这一关键词,绝影V3.0在半小时内从72小时的监控视频中快速精准定位嫌疑车辆与人员,极大压缩破案周期,凸显AI赋能实战的显著价值!
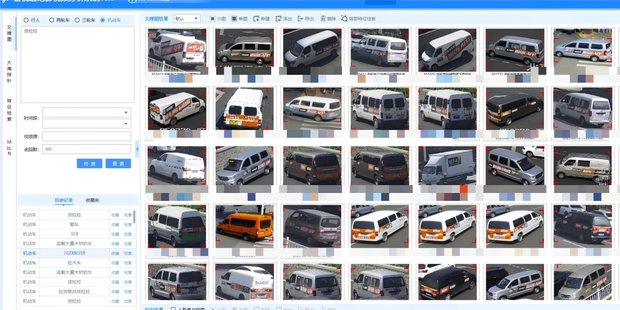
从“以图搜图”到“以文搜图”,绝影V3.0不仅扩展了视频侦查的能力边界,更重新定义了智慧警务的实战模式。让每一句模糊描述,都成为打开破局之门的关键密钥!
如需了解产品等相关问题,请联系我们。
全国统一服务热线:
4008-857-785转4、010-62670718、010-62670719
感谢您的关注与支持!


